{kind=link}
{kind=link}
A type-safe wrapper around BeautifulSoup and utilities for parsing HTML. Extracted from Open-Gov Crawlers.
This is an example from production code.
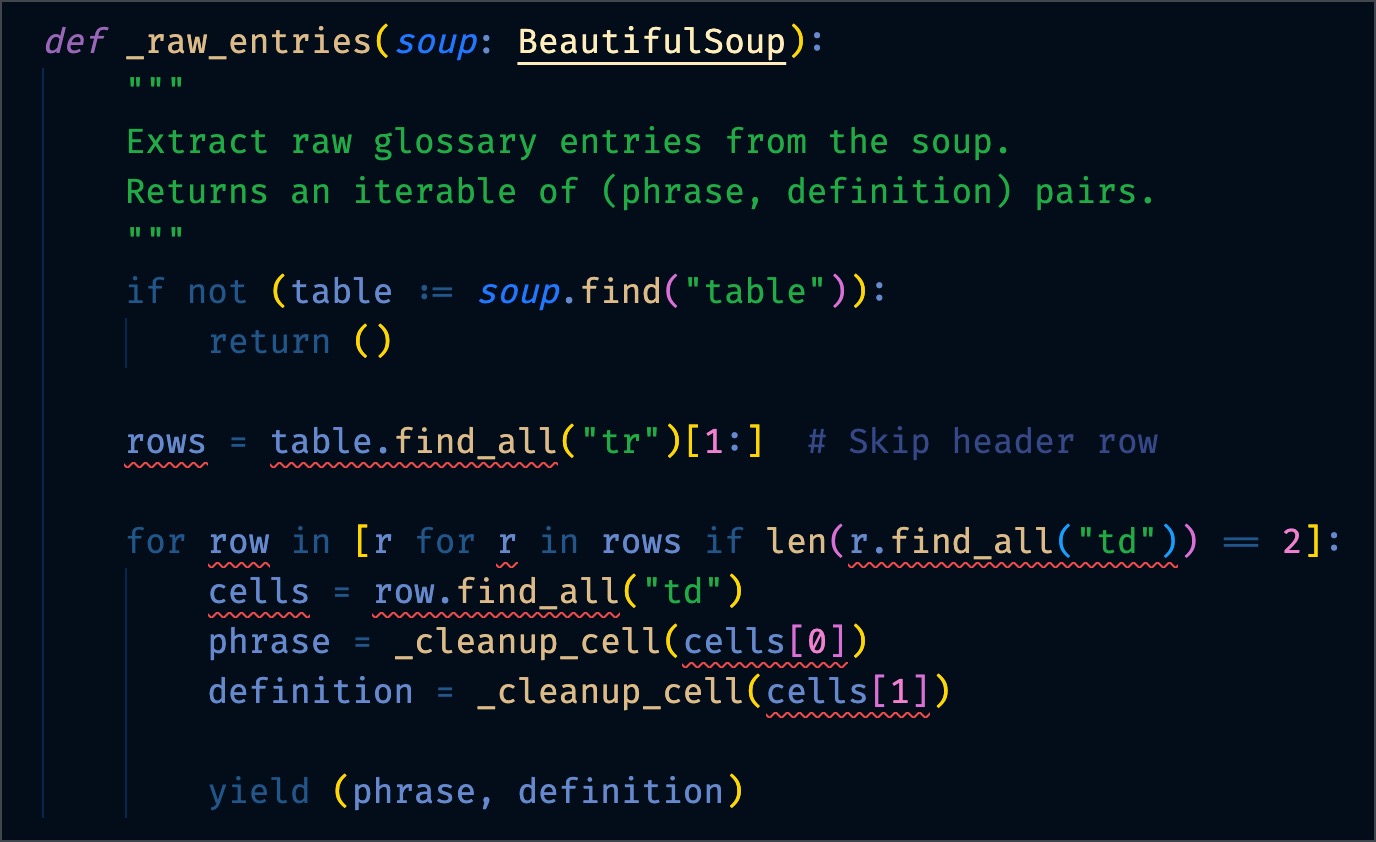
Here are the first five errors. There are 16 in total.
error: Type of "rows" is partially unknown
Type of "rows" is "list[PageElement | Tag | NavigableString] | Unknown" (reportUnknownVariableType)
error: Type of "find_all" is partially unknown
Type of "find_all" is "Unknown | ((name: str | bytes | Pattern[str] | bool | ((Tag) -> bool) | Iterable[str | bytes | Pattern[str] | bool | ((Tag) -> bool)] | ElementFilter | None = None, attrs: Dict[str, str | bytes | Pattern[str] | bool | ((str) -> bool) | Iterable[str | bytes | Pattern[str] | bool | ((str) -> bool)]] = {}, recursive: bool = True, string: str | bytes | Pattern[str] | bool | ((str) -> bool) | Iterable[str | bytes | Pattern[str] | bool | ((str) -> bool)] | None = None, limit: int | None = None, _stacklevel: int = 2, **kwargs: str | bytes | Pattern[str] | bool | ((str) -> bool) | Iterable[str | bytes | Pattern[str] | bool | ((str) -> bool)]) -> ResultSet[PageElement | Tag | NavigableString])" (reportUnknownMemberType)
error: Cannot access attribute "find_all" for class "PageElement"
Attribute "find_all" is unknown (reportAttributeAccessIssue)
error: Cannot access attribute "find_all" for class "NavigableString"
Attribute "find_all" is unknown (reportAttributeAccessIssue)
error: Type of "row" is partially unknown
Type of "row" is "PageElement | Tag | NavigableString | Unknown" (reportUnknownVariableType)
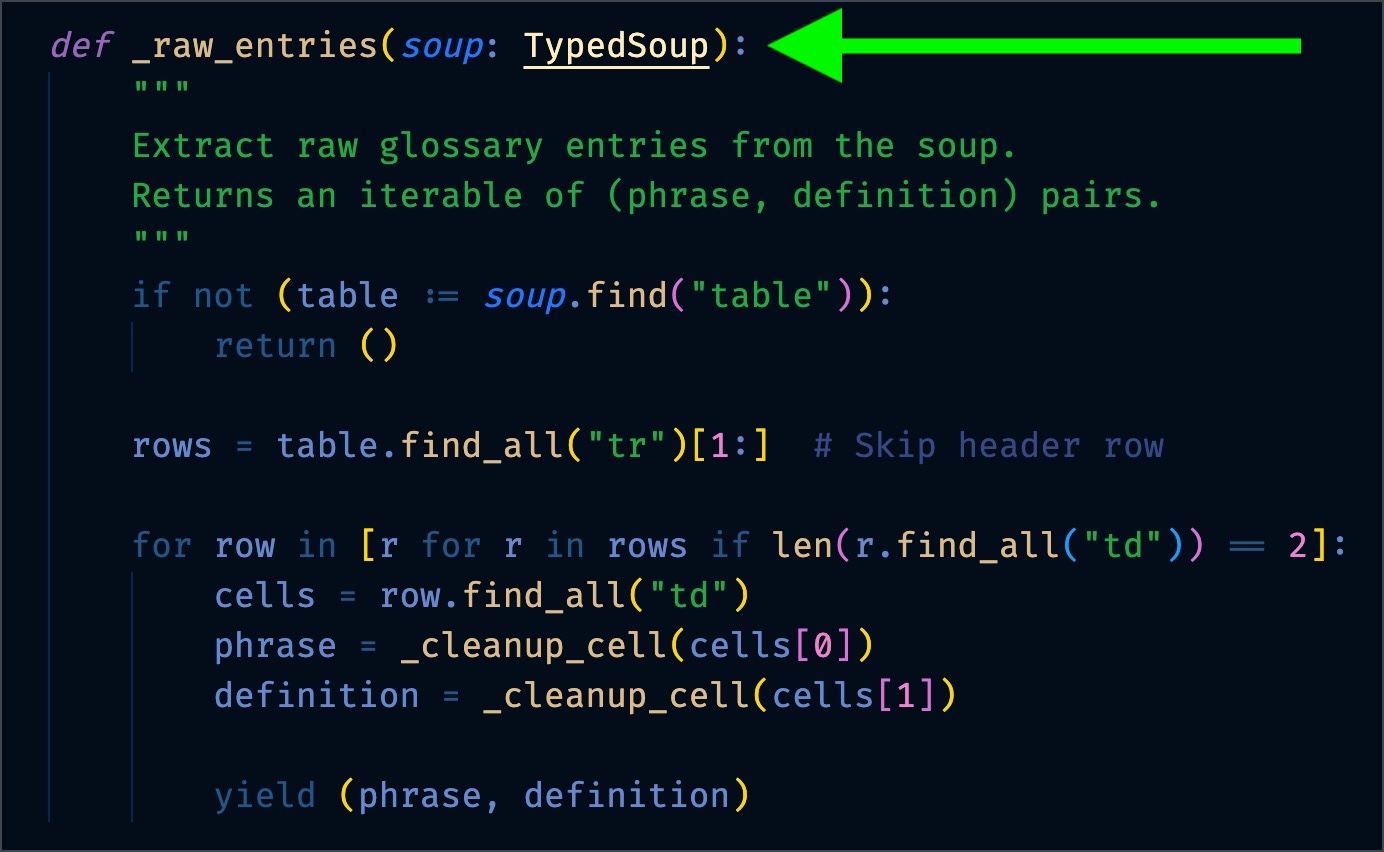
Switching out BeautifulSoup for TypedSoup provides type knowledge to the checker and IDE:
pip install typed-soupfrom typed_soup import TypedSoup
from bs4 import BeautifulSoup
# Create a type-safe soup object
soup = TypedSoup(BeautifulSoup("<div>Hello <span>World</span></div>", "html.parser"))
# Find elements with type safety
element = soup.find("span")
if element:
print(element.get_text()) # Type-safe: IDE knows this returns strWrap a BeautifulSoup object in TypedSoup to add type safety:
from typed_soup import TypedSoup
from bs4 import BeautifulSoup
soup = TypedSoup(BeautifulSoup(html_content, "html.parser"))I'm adding functions as I need them. If you have a request, please open an issue. These are the ones that I needed for a dozen spiders:
findfind_all__call__(implicit find_all, e.g.soup("p")- standard BeautifulSoup API)get_textchildrentag_nameparentnext_siblingget_content_after_elementstring
And then these help create a TypedSoup object:
TypedSoup
- All methods return properly typed results
- No more
Nonesurprises - optional values are properly typed and described in the function signatures - IDE autocomplete support for all methods
- Static type checking support with mypy/pyright
- Runtime type validation for BeautifulSoup results
This project is licensed under the MIT License.